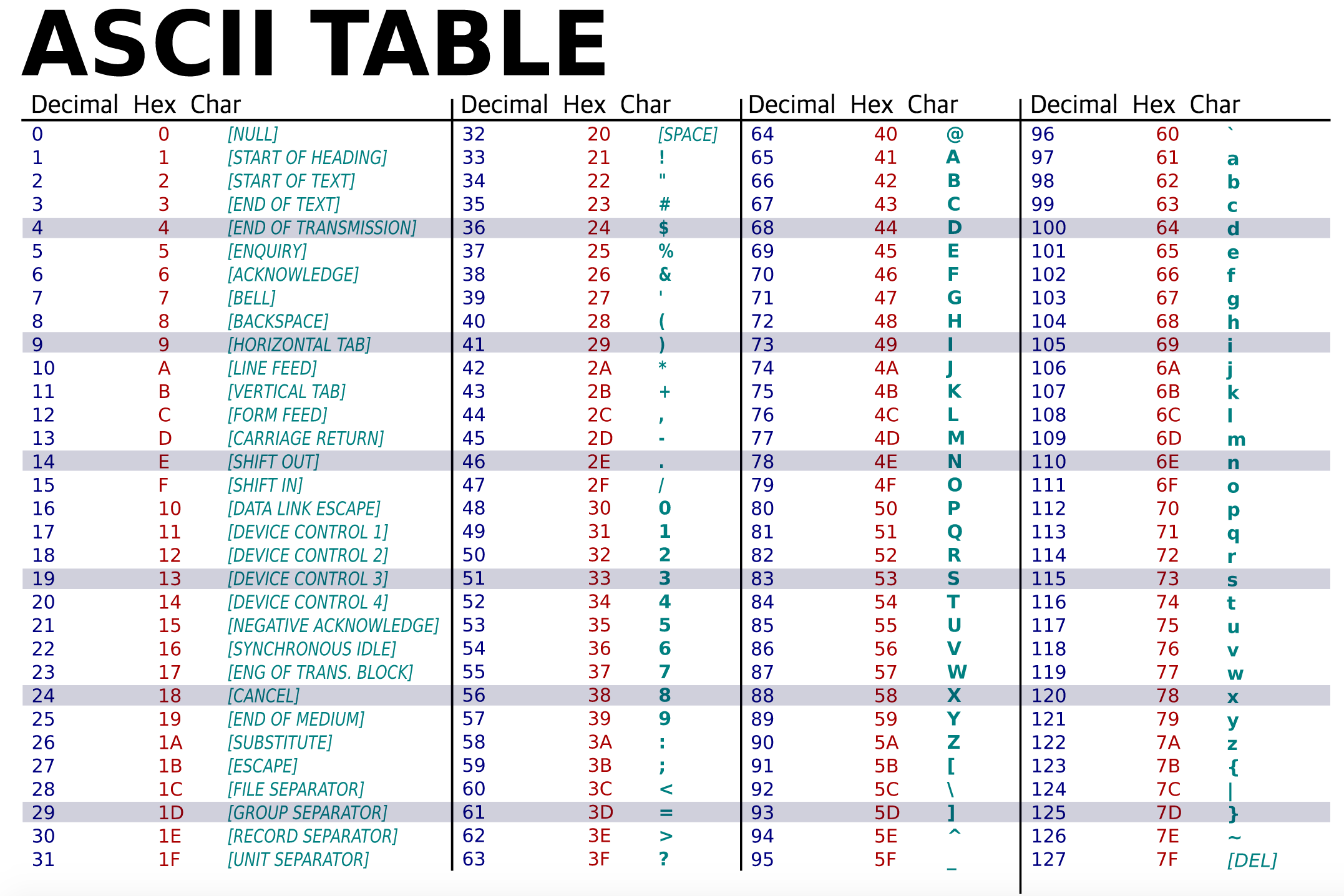
Utf 8 Table : php - reading utf-8 content from mysql table - Stack Overflow. Ansi code pages can be different on different computers, or can be changed for a single computer, leading to data corruption. The unicode® character set with equivalent character names and related characters. If you want any of these characters displayed in html, you can use the html entity found in the table below. Choose the ones you need and press ok, next select the default locale for your server and press ok. Encoding takes symbol from table, and tells font what should be painted.
The unicode® character set with equivalent character names and related characters. A 1 byte encoding is identified by the presence of 0 in the first bit. You can generate the locales you need on your server from the command line. But computer can understand binary code only. Mathematically, this is because (194%32)*64 + ( 163 %64) = 163.
7. ASCII , UNICODE, UTF-8 from wayhome25.github.io Ansi code pages can be different on different computers, or can be changed for a single computer, leading to data corruption. But computer can understand binary code only. If the character does not have an html entity, you can use the decimal (dec) or hexadecimal (hex) reference. Utf8encoding corresponds to the windows code page 65001. Encoding takes symbol from table, and tells font what should be painted. While unicode is currently 128,237 characters it can handle up to 1,114,112 characters. If you want any of these characters displayed in html, you can use the html entity found in the table below. A 1 byte encoding is identified by the presence of 0 in the first bit.
Mathematically, this is because (194%32)*64 + ( 163 %64) = 163.
Encoding takes symbol from table, and tells font what should be painted. The english alphabet a has unicode code point u+0041. Mathematically, this is because (194%32)*64 + ( 163 %64) = 163. So, encoding is used number 1 or 0 to represent characters. A character in utf8 can be from 1 to 4 bytes long. A 1 byte encoding is identified by the presence of 0 in the first bit. C1 controls and latin1 supplement. But computer can understand binary code only. Code points with lower numerical values, which tend. If you want any of these characters displayed in html, you can use the html entity found in the table below. The following table defines the available code page identifiers. Each unit (1 or 0) is calling bit. Like in morse code dots and dashes represents letters and digits.
If you want any of these characters displayed in html, you can use the html entity found in the table below. The english alphabet a has unicode code point u+0041. If the character does not have an html entity, you can use the decimal (dec) or hexadecimal (hex) reference. Character description encoded byte � Note that in html, xhtml, and xml, you can refer to any unicode character regardless of whether it has a named entity (such as €) by using a decimal character reference such as € or a hexadecimal character reference such as € (note the leading x).
Time To Share : Python Unicode from cfile9.uf.tistory.com If you want any of these characters displayed in html, you can use the html entity found in the table below. If the character does not have an html entity, you can use the decimal (dec) or hexadecimal (hex) reference. A character in utf8 can be from 1 to 4 bytes long. The english alphabet a has unicode code point u+0041. If you want any of these characters displayed in html, you can use the html entity found in the table below. A 1 byte encoding is identified by the presence of 0 in the first bit. Character subset blocks within the unicode character set. If the character does not have an html entity, you can use the decimal (dec) or hexadecimal (hex) reference.
Character description encoded byte �
Like in morse code dots and dashes represents letters and digits. If the character does not have an html entity, you can use the decimal (dec) or hexadecimal (hex) reference. Code points with lower numerical values, which tend. Note that in html, xhtml, and xml, you can refer to any unicode character regardless of whether it has a named entity (such as €) by using a decimal character reference such as € or a hexadecimal character reference such as € (note the leading x). It's binary representation is 1000001. Character description encoded byte � While unicode is currently 128,237 characters it can handle up to 1,114,112 characters. Character subset blocks within the unicode character set. C1 controls and latin1 supplement. If the character does not have an html entity, you can use the decimal (dec) or hexadecimal (hex) reference. The english alphabet a has unicode code point u+0041. Choose the ones you need and press ok, next select the default locale for your server and press ok. Each unit (1 or 0) is calling bit.
So, encoding is used number 1 or 0 to represent characters. 16 bits is two byte. A character in utf8 can be from 1 to 4 bytes long. C1 controls and latin1 supplement. Choose the ones you need and press ok, next select the default locale for your server and press ok.
Discuz! X3.4 R20210520 UTF-8 论坛标题字数突破80的限制解决方法(转) - 栗子博客 from www.lizi.tw The english alphabet a has unicode code point u+0041. The unicode® character set with equivalent character names and related characters. It's binary representation is 1000001. Encoding takes symbol from table, and tells font what should be painted. Null (u+0000) 00 start of heading (u+0001) A 1 byte encoding is identified by the presence of 0 in the first bit. If you want any of these characters displayed in html, you can use the html entity found in the table below. If the character does not have an html entity, you can use the decimal (dec) or hexadecimal (hex) reference.
A 1 byte encoding is identified by the presence of 0 in the first bit.
It's binary representation is 1000001. A 1 byte encoding is identified by the presence of 0 in the first bit. If the character does not have an html entity, you can use the decimal (dec) or hexadecimal (hex) reference. Note that in html, xhtml, and xml, you can refer to any unicode character regardless of whether it has a named entity (such as €) by using a decimal character reference such as € or a hexadecimal character reference such as € (note the leading x). The default installation contains only a limited number of locales. Choose the ones you need and press ok, next select the default locale for your server and press ok. So, encoding is used number 1 or 0 to represent characters. You can generate the locales you need on your server from the command line. C1 controls and latin1 supplement. The following table defines the available code page identifiers. Like in morse code dots and dashes represents letters and digits. While unicode is currently 128,237 characters it can handle up to 1,114,112 characters. Character description encoded byte �


Publier un commentaire